



Překlad znakové řeči
Obsah stránky
Znakovaná řeč
Pojmem znakovaná řeč rozumíme Český znakový jazyk a znakovanou češtinu. Podle zákona 155/1998 Sb. a zákona č. 384/2008 Sb. § 4 je Český znakový jazyk (ČZJ) vymezen následovně:
- Český znakový jazyk je základním komunikačním systémem těch neslyšících osob v České republice, které jej samy považují za hlavní formu své komunikace.
- Český znakový jazyk je přirozený a plnohodnotný komunikační systém tvořený specifickými vizuálně-pohybovými prostředky, tj. tvary rukou, jejich postavením a pohyby, mimikou, pozicemi hlavy a horní části trupu. Český znakový jazyk má základní atributy jazyka, tj. znakovost, systémovost, dvojí členění, produktivnost, svébytnost a historický rozměr, a je ustálen po stránce lexikální i gramatické.
- Český znakový jazyk může být využíván jako komunikační systém hluchoslepých osob v taktilní formě, která spočívá ve vnímání jeho výrazových prostředků prostřednictvím hmatu.
Podle § 6 pro znakovanou češtinu (ZČ) platí:
- Znakovaná čeština využívá gramatické prostředky češtiny, která je současně hlasitě nebo bezhlasně artikulována. Spolu s jednotlivými českými slovy jsou pohybem a postavením rukou ukazovány jednotlivé znaky, převzaté z českého znakového jazyka. Znakovaná čeština v taktilní formě může být využívána jako komunikační systém hluchoslepých osob, které ovládají český jazyk.
Základní jednotkou znakového jazyka je znak (zhruba odpovídá jednomu slovu (pojmu) v mluveném jazyce, to ale neplatí vždy). Znak má dvě složky: nemanuální a manuální. Nemanuální složka je vyjádřena mimikou, pohyby a pozicemi hlavy a horní části trupu (tzv. nemanuální nosiče). Manuální složka je vyjádřena tvary, pohyby a pozicemi rukou (tzv. manuální nosiče). Znaky se realizují ve znakovacím prostoru, který je zhruba vymezen rozpaženými lokty, temenem a linií vedenou pod žaludkem. Hlavní rozdíl mezi češtinou a ČZJ je dán tím, že ČZJ je vizuálně-motorický jazyk, tj. tento jazyk není vnímán sluchem ale zrakem a je založen na tvarech, pozicích a pohybu ne na zvuku. Z toho pramení dvě základní odlišnosti znakového jazyka: simultánnost a existence v trojdimenzionálním prostoru.
Možnosti překladu textu do znakované řeči
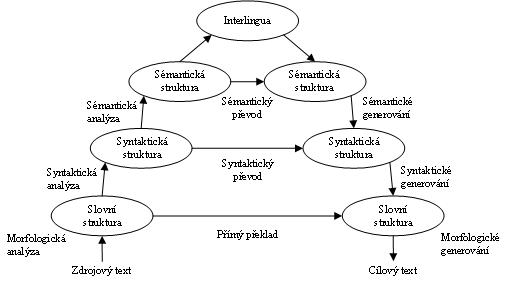
První možností jsou systémy založené na pravidlech. Tyto systémy lze podle složitosti uspořádat do tzv. Vauquisovy pyramidy, viz Obrázek Rozdělení systémů pro automatický překlad. V tomto případě:
Překlad do znakované češtiny se jeví jako snadnější, to je dáno tím, že ve znakované češtině je kladen důraz na vztah jedna k jedné (co slovo to znak) mezi českým textem a jeho překladem do znakované češtiny. Ve znakované češtině je také zachována česká gramatika, odpadá tak převod do jiného gramatického vyjádření. Při překladu tedy stačí jen nalézt ke každému slovu, které se bude překládat (některá česká slova se při překladu do znakované češtiny vynechávají), odpovídající znak a případně přidat další znaky, které jsou nezbytné pro vyjádření správného smyslu české věty (např. znaky pro zájmena, která se v české větě explicitně nevyjadřují, ve znakované češtině však ano; znak vyjadřující zápor; znak pro minulý a budoucí čas apod.). Tento překlad lze tedy plně řešit pomocí systému s architekturou přímého překladu.
Překlad textu do znakového jazyka je oproti tomu mnohem obtížnější. Je dokonce obtížnější než překlad češtiny do jiného, cizího mluveného jazyka. To proto, že v případě překladu češtiny do jiného mluveného jazyka, jde o překlad mezi jazyky, které sémantické vztahy a gramatické uspořádání ve větě vyjadřují stejně, tj. pomocí slov a ne např. využitím prostoru kolem mluvčího, jako je tomu ve znakovém jazyce. Jak již bylo řečeno, znakové jazyky jsou vizuálně-motorické jazyky, které pro vyjádření sémantických vztahů v promluvě a jim odpovídajícím gramatickým konstrukcím používají znaky a jejich prostorové uspořádání ve znakovém prostoru (simultánnost a existence v trojdimenzionálním prostoru). Vzhledem k tomu, že neexistuje psaná forma žádného znakového jazyka, která by byla přijatá a používaná neslyšícími (existují ovšem psané formy, které byly uměle vytvořeny pro potřeby slyšících uživatelů např. systém SignWriting nebo pro potřeby reprezentace znaků na počítači např. HamNoSys - notační systém, pro zápis libovolného znakového jazyka, podobný jako fonetická transkripce pro mluvenou řeč), je pořízení paralelních korpusů, které by se daly použít pro statistický přístup k řešení problému překladu, velice obtížné a nákladné. Drtivá většina systémů je tedy založena na využití lingvistického přístupu k řešení problému překladu.
 Obrázek: Rozdělení systémů pro automatický překlad.
Obrázek: Rozdělení systémů pro automatický překlad.
Statistický automatický překlad
Druhou možností je využití systémů založených na datech. V tomto případě je třeba mít k dispozici paralelní korpus, který obsahuje odpovídající si texty v obou jazycích (text ve zdrojovém a cílovém jazyce). V případě znakových jazyků je pak tento přístup komplikován tím, že neexistuje obecně používáná psaná forma žádného znakového jazyka. Je tedy obtížné získat takový to paralelní korpus z volně dostupných zdrojů. Typicky je ho třeba pro danou úlohu vytvořit zajištěním překladu zvolených textů do zvolené psané formy (i tu je třeba nejprve navrhnout) daného znakového jazyka.
Nejpoužívanější metodou používanou dnes pro statistický automatický překlad je tzv. frázový překlad. V tomto případě jsou věty ve zdrojovém i cílovém jazyce rozděleny na odpovídající fráze. Tyto fráze jsou uloženy do frázové tabulky. Při překladu nové věty jsou vybrány odpovídající cílové fráze z tabulky a uspořádány tak, aby vznikl požadovaný překlad. Pořadí frází cílové věty se může lišit od pořadí frází zdrojové věty, hovoříme pak o nemonotónním překladu. Opakem je monotónní překlad, kdy si pořadí odpovídají. Na následujícím obrázku je příklad monotónního překladu mezi češtinou a znakovanou češtinou.
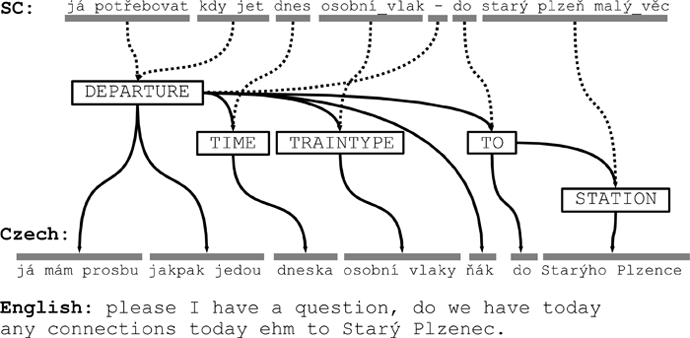 Obrázek: Příklad monotónního překladu mezi češtinou a znakovanou češtinou.
Obrázek: Příklad monotónního překladu mezi češtinou a znakovanou češtinou.