



Sign language translation
Content
Signed speech
The term signed speech means Czech sign language and Signed Czech. According to law 155/1998 Sb. and law 384/2008 Sb. § 4 is Czech sign language (CSE) defined as follows:
- Czech sign language is basic communication system of hearing impaired persons in the Czech Republic, who considered it as the main form of their communication.
- The CSE is a natural and adequate communication form and it is composed of the specific visual-spatial resources, i.e. hand shapes (manual signals), movements, facial expressions, head and upper part of the body positions (non-manual signals). CSE has basic language attributes, i.e. system of signs, double articulation, peculiarity and historical dimension, and has its own lexical and grammatical structure.
- Czech sign language can be used for communication of deafblind persons in tactile form, which consists in perception of CSE via sense of touch.
According to § 6 is Signed Czech (SC) defined as follows:
- SC uses grammatical and lexical resources of the Czech language. During the SC production, the Czech sentence is audibly or inaudibly articulated and simultaneously the CSE signs of all individual words of the sentence are signed.
The basic item of sign language is the sign (mostly matches one word or concept in spoken language but this do not hold true in any case). Each sign is composed from two components: the manual and non-manual. The non-manual component expresses the gesture of face, the motion and position of head and other parts of upper body. The manual component is expressed by shapes, motions and positions of hands. The signs are realized in a sign space. The sign space is approximately specified by the top of head, elbows sideways raise, and horizontal line below stomach. The main difference between spoken Czech and CSE is that the CSE is visual-spatial language. It means that CSE is not perceived by ears but eyes, is based on shapes and motions in space.
The possibilities of automatic translation to signed speech
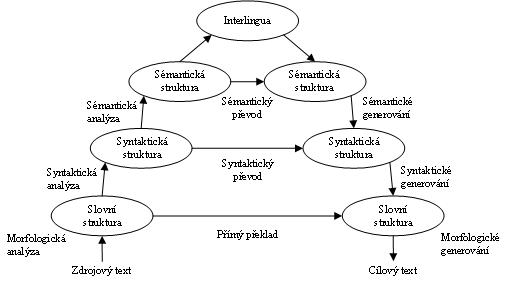
The first possibility are the rule-based systems. These systems can be arranged according to its complexity into the so-called Vauquis pyramid, see Picture Organization of systems for automatic translation. In this case:
The translation to the Signed Czech seems like easier problem. This is because in the SC is attempt to preserve one to one relation (each word is a sign) between the Czech text and its translation to SC. In addition SC preserves the Czech grammar. During the translation it is only needed to find corresponding sign for every translated Czech word (some words are omitted) and possibly add some other signs, which are necessary for correct translation. So, this problem can be solved by translation system with the direct architecture.
In opposite, the translation to the sign language is more complicated problem. Even, it is more complicated than the translation from Czech to another spoken language. In the case of translation between Czech and another spoken language it is translation between languages, which express semantic relations and grammatical order in the sentence in the same fashion, i.e. by words and not for example using of space around signer. Because there is no written form of any sign language using by the deaf (but exists written forms artificially created for using by hearing users for example SignWriting or HamNoSys - notation system for sign representation in computer) is acquisition of parallel corpuses needed for statistical translation difficult and expensive task. Thus, the most of the existing translation system is based on using of linguistic approach to the solution of translation.
 Picture: Organization of systems for automatic translation.
Picture: Organization of systems for automatic translation.
Statistical automatic translation
The second possibility is using of systems based on data. In this case, the parallel corpus, which contains appropriate texts in both languages (source and target language), is needed. As we said before, there is no written form of any sign language. So it is difficult to obtain such corpus from freely available sources. Typically, the corpus have to be created by translation of chosen texts into the required written form (usually it have to be designed too) of given sign language.
The state of the art method for statistical automatic translation today is phrase-based translation. The source and target sentence are divided to corresponding phrase pairs, which are stored in the phrase table. During the translation of new sentence the appropriate target phrases are chosen from the table and compose to get searched translation. Generally, there can be different order of source and target phrases then we speak about non-monotone translation. The opposite is monotone translation where is the order preserved. There is an example of monotone translation between Czech and Signed Czech on the next picture.
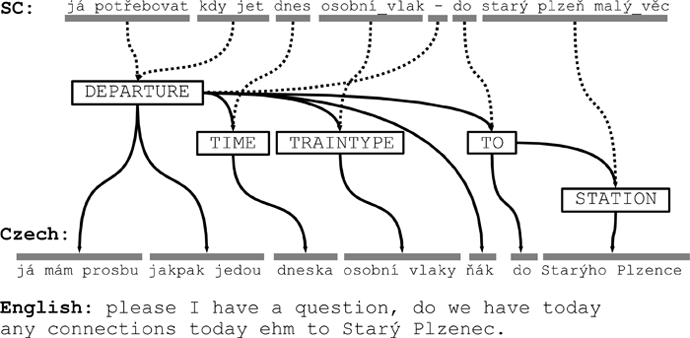 Picture: The example of monotone translation between Czech and Signed Czech.
Picture: The example of monotone translation between Czech and Signed Czech.