



Rozpoznávání znakového jazyka
Obsah stránky
Cílem rozpoznávání znakového jazyka je rozpoznat promluvu znakujícího člověka. Rozpoznaná informace je následně předána modulu překladu znakového jazyka, který jí přeloží do srozumitelné formy. Vstupem pro rozpoznávač je sekvence snímků, zachycena například kamerou. Obecně je možné použít i jíný snímací přistroj jako například datové rukavice.

Obrázek 1: Postup sledování pohybu rukou a hlavy.
a) původní snímek b) detekce barvy kůže c) detekce rukou a hlavy d) trajektorie pohybu rukou celého znaku e) detekce polohy hlavy, očí a úst
Pro úspěšné rozpoznání je potřeba detekovat a vhodně popsat manuální a nemanuální složku znakového jazyka. Manuální složka se skláda z tvaru rukou, pohybu rukou, orientace rukou a místa artikulace. Nemanuální složku tvoří výraz v obličeji, artikulace rtů, póza těla, rychlost promluvy, atd.
Tracking
Pro detekování trajektorie rukou se využivá sledovací algoritmus (tracking). Ten je schopen sledovat objekt v po sobě jdoucích snímcích, za předpokladu, že pohyb je spojitý a objekt neměni rapidně svůj vzhled. Ruce jsou ovšem vzhledově složitý objekt a navíc jedna může "napodobovat" druhou. Největší problém nastává, když jsou ruce překryté. To, co je pro člověka samozřejmost a je schopen situaci vyhodnotit během okamžiku, je pro počítač nesrovnatelně těžší úkol. Navíc při znakování jsou pohyby poměrně rychlé a k překryvům dochází často.
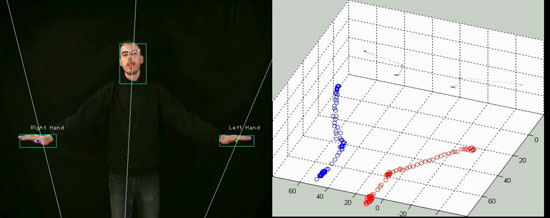
Obrázek 2: 3D sledování pohybu rukou a hlavy (s využitím 2 kamer).
a) původní snímek + detekovaná hlava a ruce b) trajektorie pohybu rukou ve 3D prostoru
Důležitá část nemanuální složky je tvar rtů. Ten se zkoumá i u audiovizuálního rozpoznávání řeči a analogicky se dá převést na problém rozpoznávání znakového jazyka. Výraz v obličeji se dá zkoumat jako emoce.
Fáze rozpoznávání
Po vytvoření vhodného popisu pozorovaných obrázků nastává samotná fáze rozpoznávání. Většinou se jedná a statistický přístup, napřiklad pomocí skrytých Markovových modelů. Ten lze popsat tak, že postupně systém učíme. Předkládáme mu různé příklady konkrétního znaku a ty statisticky popíšeme. Při rozpoznávání pak model vyhodnotí pravděpodobnost námi pozorovaného neznámého znaku.