



Sign language recognition
The goal of Sign Language Recognition is to recognize a sign language utterance. The recognized information is then passed to a module of sign language translation. This module translates the information to an uderstandable form. The input of the recognizer is a sequence of images. They can be captured by a camera. Generally, it is possible to use different capturing device such as data gloves.

Figure 1: Hand and head tracking.
a) original image b) skin color detection c) hands and head detection d) hand trajectories e) head, eyes and mouth detection
For a successful recognition it is required to detect and describe the manual and non-manual component of the language. The manual component is composed of the handshape, the hand movement and orientation and the location of articulation. The non-manual component is composed of the face expression, lip articulation, pose of the body, velocity of the utterance and so on.
Tracking
For the detection of the hand trajectory a tracking algorithm is used. It is able to track an object in consecutive frames, provided that the movement is continuous and the object doesn't change rapidly in appearance. The hands are however a relatively complex articulator. Moreover one hand can "mimic" the other. The biggest problem occures when the hands are in occlusion. For a person it is very easy to "see" what is happening, but for a computer it is a very computational expensive task. Moreover, when signing the movements are relatively fast and the occlusions occure often. When occluded we aren't able to track the shape of the occluded hand and our chances of correctly determine which hand is left and which hand is right are lowered significantly.
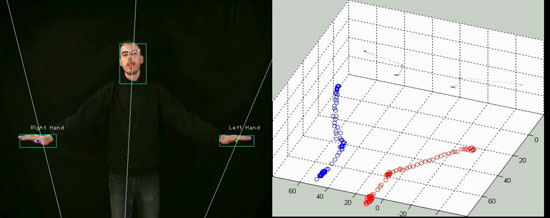
Figure 2: 3D hand and head tracking (using 2 cameras).
a) original image + hand and head detection b) 3D hand tracking
Important part of the non-manual component is the shape of the lips. This research falls into the audio-visual speech recognition and can be analogically applied to the problem of sign language recognition. The face expression can be seen as the emotion recognition.
Recognition phase
After creating a proper description of the observed images, this description (features) is passed to the recognizer. The recognizer is usually of statistical nature, for example a Hidden Markov Model. It can be explaind as a learning system. We provide it with different examples of a sign and the model is building a statistical description of the sign. For an unknown observed sign a model will provide us with a probability with which it generates the observation.