



Vyhledávání informací
Obsah stránky
Úkolem automatického vyhledávání informací (information retrieval) je předložit uživateli seznam dokumentů (seřazený podle klesající relevance), které co nejlépe uspokojí jeho informační potřebu vyjádřenou pomocí dotazu zadaného v přirozeném jazyce. V ideálním případě tedy algoritmy vyhledávání informací dokáží správně sémanticky interpretovat jak obsah všech dokumentů v dané množině, tak samozřejmě i zadaného dotazu. V praxi dosud této mety dosaženo nebylo, přesto i dílčí úspěchy na tomto poli výrazně pomáhají uživatelům najít potřebné informace. Techniky, které jsou v současné době u nás i ve světě používány, sémantický obsah dokumentu i dotazu aproximují statistickou analýzou slovních n-gramů, které se v daném dokumentu či dotazu vyskytují. Tímto způsobem dokážeme určit míru podobnosti mezi dokumenty a dotazem a tuto podobnost použít jako měřítko relevance. Mírnou modifikací těchto algoritmů řešíme i úlohy kategorizace dokumentů, sdružování podobných dokumentů a segmentace souvislého textu. Je třeba mít na zřeteli, že definice pojmu „dokument“ je pro jednotlivé úlohy rozdílná – může jít o celá literární díla, webové stránky, novinové články až po nejmenší jednotky jako odstavec a samostatná věta.
Naší specializací je vyhledávání informací v řečových datech, kdy je úloha ztížena přítomností chyb v rozpoznaném textu. Snažíme se proto co nejlépe využít toho, že máme z rozpoznávače k dispozici nejen nejlepší (nejpravděpodobnější) přepis daného zvukového záznamu, ale celou síť (mřížku, lattice) nejpravděpodobnějších hypotéz a to i s ohodnocením jejich důvěryhodnosti.
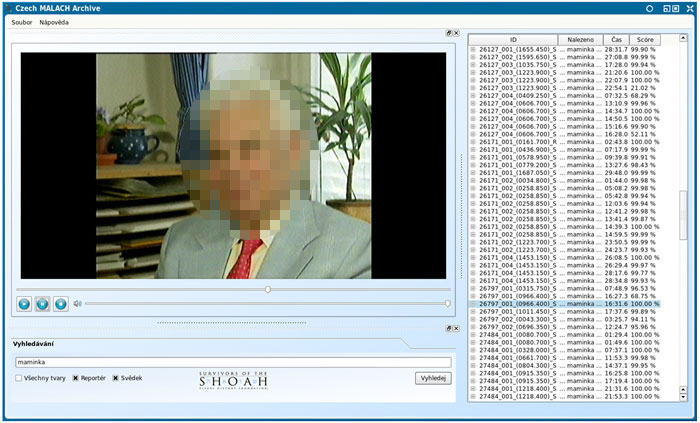
Speciální podúlohou vyhledávání informací v řeči je vyhledávání jednotlivých slov či krátkých frází. Tuto úlohu se nám již podařilo dotáhnout do fáze praktické aplikace, která umožňuje uživatelům vyhledávat a přehrávat části záznamů obsahující daná klíčová slova v česky mluvené části rozsáhlého audiovizuálního archivu svědků Holokaustu (cca 1000 hodin – více o archivu na http://dornsife.usc.edu/vhi). Vzhledem k tomu, že aplikace dokáže vyhledávat ve slovní i ve fonetické reprezentaci jednotlivých promluv, lze najít i slova neobsažená ve slovníku rozpoznávače. Tato aplikace se v současné době připravuje ke zprovoznění v Centru vizuální historie Malach (http://ufal.mff.cuni.cz/cvhm/).
Mnohé závěry výzkumů však naznačují, že zdaleka nejlepších výsledků při vyhledávání lze dosáhnout, pokud jsou data v daném archivu již předem označena klíčovými slovy vybíranými z vhodně navrženého řízeného slovníku (tzv. tezauru), často hierarchicky strukturovaného.
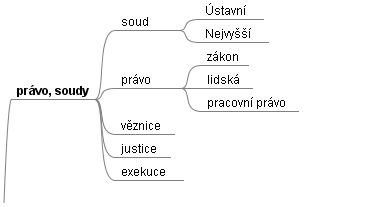
Přípravou či výběrem vhodného tezauru spolu s návrhem metod pro asistovanou katalogizaci (přiřazení klíčových slov jednotlivým dokumentům) se v současné době zabýváme mimo jiné ve společném projektu s Českou televizí.
Špičkové techniky rozpoznávání a syntézy řeči vyvinuté na naší katedře spolu s pokročilými algoritmy zpracování přirozeného jazyka od týmu Ústavu formální a aplikované lingvistiky MFF UK byly v rámci evropského projektu COMPANIONS integrovány do dialogového systému, který je v omezené míře schopen konverzovat s uživatelem o jeho rodinných fotografiích.