



Audiovizuální rozpoznávání řeči
Obsah stránky
Jedná se o úlohu rozpoznávání řeči počítačem, v níž je využíváno obou složek řeči: akustické složky a vizuální složky. Řeč je produkována řečovým ústrojím a výsledkem produkce řeči člověkem je akustický signál, který můžeme slyšet a pohyb řečového ústrojí, který můžeme vidět. Bohužel viditelnou část hlasového ústrojí představují pouze rty, zuby, jazyk a tváře člověka. Proto vizuální složka řeči obsahuje méně informace než akustická složka řeči. Vizuální složku řeči využívají nejen lidé se sluchovým postižením (odezírání ze rtů), ale používáme ji nevědomě všichni v běžné komunikaci především v hlučných prostředích.
Schéma
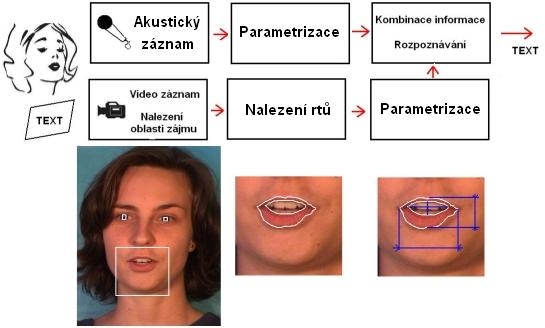 Obrázek: Schéma audiovizuálního rozpoznávání řeči. Celý proces rozpoznávání se skládá ze dvou částí. Akustická část a vizuální část. Tyto dvě větve procesu mohou být vzájemně propojeny v některých bodech procesu. Vizuální část se skládá ze tří základních bloků. Blok nalezení oblasti zájmu: stará se o nalezení hlavy řečníka a určení polohy úst v obraze. Blok parametrizace: jeho úkolem je vhodně popsat vizuální řeč tak aby tento popis obsahoval co nejvíce informace o řeči a žádnou informaci o řečníkovi (do tohoto bloku patří i pod blok nalezení rtů). Blok rozpoznávání: provádí kombinaci akustického a vizuálního popisu řeči a samotné rozpoznávání.
Obrázek: Schéma audiovizuálního rozpoznávání řeči. Celý proces rozpoznávání se skládá ze dvou částí. Akustická část a vizuální část. Tyto dvě větve procesu mohou být vzájemně propojeny v některých bodech procesu. Vizuální část se skládá ze tří základních bloků. Blok nalezení oblasti zájmu: stará se o nalezení hlavy řečníka a určení polohy úst v obraze. Blok parametrizace: jeho úkolem je vhodně popsat vizuální řeč tak aby tento popis obsahoval co nejvíce informace o řeči a žádnou informaci o řečníkovi (do tohoto bloku patří i pod blok nalezení rtů). Blok rozpoznávání: provádí kombinaci akustického a vizuálního popisu řeči a samotné rozpoznávání.
Problém rozpoznávání řeči v hlučných prostředích. Akustický šum ovlivňuje pouze akustickou složku řeči a proto se vizuální rozpoznávání využívá právě jako podpora akustického rozpoznávání v hlučných prostředích.
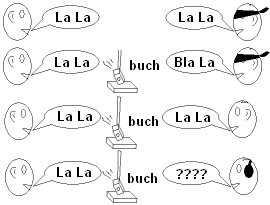 Obrázek: Jak využít vizuální informaci.
Obrázek: Jak využít vizuální informaci.
Definice
Audio vizuální rozpoznávání řeči, je rozpoznávání řeči člověkem nebo strojem při němž je využívána jak akustická tak vizuální část řeči. Vizuální složkou řeči rozumíme viditelnou část řečového traktu. Protože k tvorbě řeči přispívá i část řečového traktu, která není viditelná, obsahuje vizuální složka řeči méně informace o řeči než akustická složka řeči. Vizuální složku řeči používají především lidé sluchově postižení. Pro neslyšící je vizuální část řeči jediná informace o řeči. Odezírání je tedy rozpoznávání řeči z vizuální složky řeči. Odezírání však používají i lidé, kteří nejsou sluchově postiženi. Používají ho k zvýšení úspěšnosti rozpoznávání řeči tam kde je akustická složka řeči zatížena šumem. Při rozpoznávání řeči počítačem se vizuální složka řeči používá také jako podpora rozpoznávání z akustické složky řeči. Tak jako v jiných úlohách i při audiovizuálním rozpoznávání řeči počítačem se vychází ze zkušeností lidských expertů na odezírání. Sluchově postižení dosahují úspěšnosti odezírání maximálně 60-80% v závislosti na podmínkách odezírání. Nejdůležitější podmínky odezírání jsou kvalita vizuální řeči řečníka (správná artikulace), úhel pohledu, osvětlení, stav odezírajícího člověka atd. Kvalita vizuální řeči člověka je velmi závislá na řečníkovi. Je dokázáno že člověk, kterému je dobře rozumět z akustické složky řeči nemusí mít dobře odezřetelnou vizuální řeč. Při učení řeči totiž nemáme zpětnou odezvu zda je naše vizuální řeč správná či nikoliv. V úloze odezírání se jako základní řečové jednotky používají vizémy. Vizém je skupina fonémů, které mají podobný řečový obraz (vizuální složku řeči). Například fonémy p,b,m tvoří jedem vizém. Pro češtinu se většinou uvádí 13 různých vizémů. Podobnosti jednotlivých vizémů jsou způsobeny menším množstvím informace o řeči obsažené ve vizuální složce řeči. Velkým problémem při odezírání je tzv. ovlivňování jednotlivých vizémů vyslovených v jenom slově (koartikulace). Z tohoto hlediska rozdělujeme vizémy na ovlivňované a ovlivňující. Podle toho jak po sobě následují ve slově se může změnit mluvní obraz vizému v důsledku působení okolních vizémů. Tento jev odezírání velmi ztěžuje.
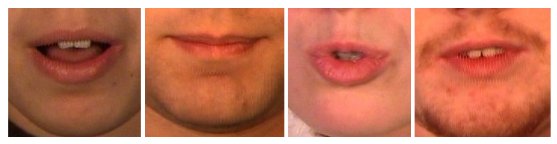 Obrázek: Jaká hláska se skrývá pod obrázkem? Zde si můžete ověřit zda dokážete určit promlouvanou hlásku jen podle obrázku. Klikněte na obrázek a zobrazí se správná odpověď.
Odpověď je: e,p,o,v
Obrázek: Jaká hláska se skrývá pod obrázkem? Zde si můžete ověřit zda dokážete určit promlouvanou hlásku jen podle obrázku. Klikněte na obrázek a zobrazí se správná odpověď.
Odpověď je: e,p,o,v
Audio-vizuální korpus
Audio vizuální korpus: Abychom mohli ověřit námi navržené metody audio vizuálního rozpoznávání, vytvořili jsem databázi laboratorních audio vizuálních nahrávek neboť existuje pouze jedna audiovizuální databáze pro český jazyk (nepoužitelná pro naše účely). Databáze byla nahrána tak, aby její zpracování (nalezení hlavy, nalezení rtů) bylo co nejednodušší a co nejpřesnější. Na této databázi budou provedeny testy audiovizuální rozpoznávání spojité řeči.
Parametry korpusu:
- Počet řečníků: 100 řečníků, 39 mužů, 61 žen
- Jazyk: čestina
- Počet promluv: 200 pro každého řečníka, prvních 50 společných pro všechny.
- Typ promluv: spojitá řeč, foneticky vyvážené věty
- Video záznam: čelní pohled, 720*576*25fps, DV codec
- Akustický záznam: 2 mikrofony, 44kHz, 16 bit, PCM
Akutický a vizuální záznam byly nahrány odděleně a pro jejich synchronizaci byla použita klapka. Všechny promluvy byly ručně přepsány a bylo provedeno předzpracování video záznamu. Předzpracování provedlo nalezení hlavy řečníka a oblasti zájmu ROI (oblast rtů). Veškeré tyto informace byly uloženy na DVD.
 Obrázek: Nahrávání korpusu.
Obrázek: Nahrávání korpusu.
 Obrázek: Řečníci.
Obrázek: Řečníci.Popis rtů pro rozpoznávní
Jestliže jsme získali kontury rtů, můžeme provést výpočet popisu vizuální složky řeči (získání příznaků). Popis nám vlastně převádí jednotlivé tvary rtů, nastavení jazyka atd. na čísla. Vizuální složka řeči se velmi liší pro různé řečníky. Ne každý člověk, kterému je dobře rozumět z akustické složky řeči, musí mít dobře odezřetelné mluvní obrazy. Popis vizuální složky řeči by měl být nezávislý na řečníkovi. To znamená, že popis je podobný pro různé řečníky a stejné fonémy. Na druhou stranu musí být popis dostatečně odlišný pro odlišné fonémy u jednoho řečníka. Existují dva základní druhy popisů: obrazový, tvarový. Popis založený na obraze pracuje s celou oblastí ROI. Jako popis bere jednotlivé body této oblasti a pomocí metod redukce informace (nadbytečné) se snaží získat popis. Metody založené na tvaru potřebují získat konturu rtů. Po té se snaží popsat jednotlivé části obličeje, které jsou důležité při odezírání (okrouhlost rtů, výška rtů, šířka rtů)
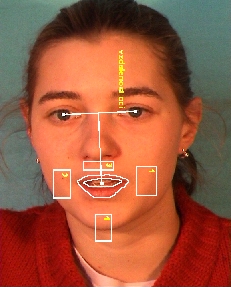 Obrázek: Náš popis je založen na znalostech experta, který umí odezírat ze rtů. Jednotlivé příznaky se snaží popsat dominantní vizuální část pro jednotlivé fonémy. Příznaky jsou zvoleny tak, aby nepopisovali konkrétní velikosti rtů (šířka, výška), neboť ta je závislá na řečníkovi. Jedním z příznaků je dotyk horního a dolního rtu. Tento příznak je důležitý pro skupinu fonémů p,b,m. Další příznak je okrouhlost rtů (o,u). Mezi další příznaky patří dotyk horních zubů a spodního rtu, pozice horních zubů, pozice dolních zubů, pozice jazyka, pohyb horního rtu, pohyb dolního rtu, pohyb a deformace oblastí kolem úst, pohyb brady, tvar rtů, vzájemné polohy jednotlivých částí.
Obrázek: Náš popis je založen na znalostech experta, který umí odezírat ze rtů. Jednotlivé příznaky se snaží popsat dominantní vizuální část pro jednotlivé fonémy. Příznaky jsou zvoleny tak, aby nepopisovali konkrétní velikosti rtů (šířka, výška), neboť ta je závislá na řečníkovi. Jedním z příznaků je dotyk horního a dolního rtu. Tento příznak je důležitý pro skupinu fonémů p,b,m. Další příznak je okrouhlost rtů (o,u). Mezi další příznaky patří dotyk horních zubů a spodního rtu, pozice horních zubů, pozice dolních zubů, pozice jazyka, pohyb horního rtu, pohyb dolního rtu, pohyb a deformace oblastí kolem úst, pohyb brady, tvar rtů, vzájemné polohy jednotlivých částí.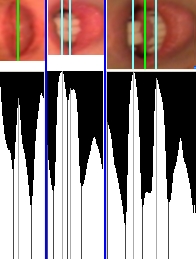 Obrázek: Velice důležitou složkou vizuální informace je viditelnost a pozice jednotlivých částí uvnitř úst. Viditelné jsou pouze zuby a částečně jazyk. Pozici těchto objektů zjišťujeme pomocí analýzy jedné řádky vnitřku rtů. Tato řádka nese všechny potřebné informace o zbytku úst, protože pohyb zubů a jazyka se během promluvy odehrává pouze ve vertikální oblasti. Pohyby v horizontálním směru nemají pro řeč význam. Analýza řádky je založena na vyhledávání maxim a minim v šedotónové reprezentaci.
Obrázek: Velice důležitou složkou vizuální informace je viditelnost a pozice jednotlivých částí uvnitř úst. Viditelné jsou pouze zuby a částečně jazyk. Pozici těchto objektů zjišťujeme pomocí analýzy jedné řádky vnitřku rtů. Tato řádka nese všechny potřebné informace o zbytku úst, protože pohyb zubů a jazyka se během promluvy odehrává pouze ve vertikální oblasti. Pohyby v horizontálním směru nemají pro řeč význam. Analýza řádky je založena na vyhledávání maxim a minim v šedotónové reprezentaci.Ukázky nalezení kontury rtů:
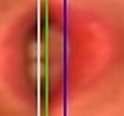
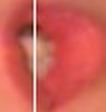
Nalezení kontury rtů
Nalezení kontury rtů vychází z výsledků metody hledání hlavy řečníka. Pracuje se pouze s oblastí zájmu ROI. Metoda se snaží nalézt vnitřní a vnější konturu rtů řečníka. Nalezení kontury rtů se používá pouze v případě, že jako popis vizuální složky řeči chceme použít tvarové příznaky. Existuje několik způsobů vyhledávání kontur rtů, které vycházejí z tvaru rtů, z barvy rtů či z pohybu rtů. Úspěšnost algoritmu je opět závislá na několika faktorech. Především je to úhel natočení rtů, osvětlení či odlišnost rtů od obličeje řečníka. Postup řešení:
 Obrázek: Pro nalezení kontury rtů je nejprve nutné určit přibližný tvar rtů. To provedeme metodou popsanou v kapitole nalezení hlavy. Metoda pracuje na principu odlišnosti barvy kůže a rtů. Pomocí metody prahování získáme binární obraz rtů. Z obrázků je patrné, že v obraze se nenachází pouze objekt rtů a kůže, ale i objekty zubů, jazyka a vnitřku úst. Výsledek prahování dokáže dobře odlišit kůži a rty ale již hůře odlišuje vnitřek rtů od samotných rtů.
Obrázek: Pro nalezení kontury rtů je nejprve nutné určit přibližný tvar rtů. To provedeme metodou popsanou v kapitole nalezení hlavy. Metoda pracuje na principu odlišnosti barvy kůže a rtů. Pomocí metody prahování získáme binární obraz rtů. Z obrázků je patrné, že v obraze se nenachází pouze objekt rtů a kůže, ale i objekty zubů, jazyka a vnitřku úst. Výsledek prahování dokáže dobře odlišit kůži a rty ale již hůře odlišuje vnitřek rtů od samotných rtů.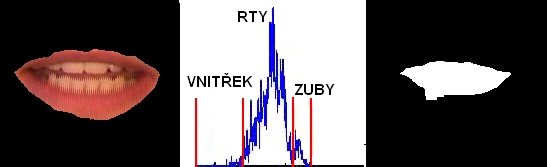 Obrázek: Proto celý postup prahování opakuje. Jako oblast zájmu se nyní použije celý uzavřený objekt nalezených rtů. V této oblasti jsou dominantní objekt rty a vše ostatní je vnitřek rtů. Výsledný obraz kombinujeme z předchozím výsledkem a získáme binární obraz samotných rtů.
Obrázek: Proto celý postup prahování opakuje. Jako oblast zájmu se nyní použije celý uzavřený objekt nalezených rtů. V této oblasti jsou dominantní objekt rty a vše ostatní je vnitřek rtů. Výsledný obraz kombinujeme z předchozím výsledkem a získáme binární obraz samotných rtů.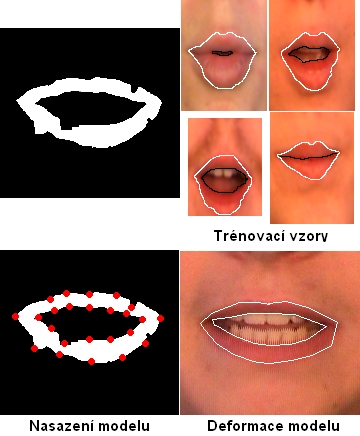 Obrázek: Výsledný binární obraz rtů již zachycuje správný tvar ovšem může obsahovat chyby, které je nutné opravit. Chyby vznikají v případech kdy je barva rtů podobná barvě obličeje (červené fleky na obličeji, špatné osvětlení). Velký problém při hledání vnitřku úst představuje nalezení jazyka, neboť jeho barva je téměř stejná jako barva rtů. Pro opravu tvaru rtů je použit model rtů. Model rtů jsme nejprve vytvořili z trénovací množiny. Trénovací množinu představují různé tvary rtů pro zůzné řečníky, kde je ručně označena vnější a vnitřní kontura rtů. Model se skládá z n bodů rozprostřených po kontuře. Využitím metody PCA můžeme deformovat tento model menším počtem řídících parametrů než je počet bodů, tak aby zaujímal tvary z trénovací množiny. Jestliže tedy chceme opravit nalezenou konturu rtů, jednotlivé body modelu posuneme do nalezených bodů a necháme je zdeformovat podle trénovacích dat. Tím opravíme drobné nepřesnosti a získáme vnitřní a vnější konturu rtů.
Obrázek: Výsledný binární obraz rtů již zachycuje správný tvar ovšem může obsahovat chyby, které je nutné opravit. Chyby vznikají v případech kdy je barva rtů podobná barvě obličeje (červené fleky na obličeji, špatné osvětlení). Velký problém při hledání vnitřku úst představuje nalezení jazyka, neboť jeho barva je téměř stejná jako barva rtů. Pro opravu tvaru rtů je použit model rtů. Model rtů jsme nejprve vytvořili z trénovací množiny. Trénovací množinu představují různé tvary rtů pro zůzné řečníky, kde je ručně označena vnější a vnitřní kontura rtů. Model se skládá z n bodů rozprostřených po kontuře. Využitím metody PCA můžeme deformovat tento model menším počtem řídících parametrů než je počet bodů, tak aby zaujímal tvary z trénovací množiny. Jestliže tedy chceme opravit nalezenou konturu rtů, jednotlivé body modelu posuneme do nalezených bodů a necháme je zdeformovat podle trénovacích dat. Tím opravíme drobné nepřesnosti a získáme vnitřní a vnější konturu rtů.Nalezení hlavy a oblasti zájmu ROI
Detekce hlavy slouží k nalezení tzv. oblasti zájmu (většinou rty a okolí označované jako ROI) pro každý snímek video záznamu promluvy. Metody nalezení hlavy je možné rozdělit na dva základní přístupy. Metody založené na vyhledávání významných bodů a metody založené na vyhledávání tváří. Metody založené na vyhledávání významných bodů se orientují na nalezení očí, nosních dírek, úst, obočí , a dalších relativně odlišných bodů lidské hlavy. Podle jejich umístění potom určují oblast zájmu. Metody vyhledávání tváří prohledávají jednotlivé části obrazu a porovnávají tyto části se vzory obličejů a pozadí získaných ze vzorových obrazů. Složitost úlohy závisí na možnostech pohybu hlavy řečníka, na osvětlení scény či na pozadí scény. Pro naši úlohu (laboratorní databáze)jsme zvolili následující omezující podmínky :pohyby hlavy jsou minimální, osvětlení je konstantní a pozadí tvoří jednolitá modrá plocha. Postup řešení:
 Obrázek: Metody nalezení hlavy využívají charakteristické barvy lidské kůže. Barva lidské kůže je ve speciální barevné reprezentaci YCBCR velice podobná pro velkou množinu lidí a proto známe-li hodnotu barvy kůže , můžeme pomocí prahování získat binární obraz hlavy řečníka [1]. Barva kůže je získána z jednoho framu promluvy daného řečníka.
Obrázek: Metody nalezení hlavy využívají charakteristické barvy lidské kůže. Barva lidské kůže je ve speciální barevné reprezentaci YCBCR velice podobná pro velkou množinu lidí a proto známe-li hodnotu barvy kůže , můžeme pomocí prahování získat binární obraz hlavy řečníka [1]. Barva kůže je získána z jednoho framu promluvy daného řečníka.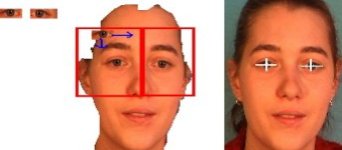 Obrázek: Jestliže známe přibližný tvar hlavy provedeme nalezení významných bodů. Jako první nalezneme oči. Pro každého řečníka vytvoříme vzor pro levé a pravé oko. Protože známe umístění očí na obličeji a nalezený tvar obličeje, můžeme určit přibližné místo výskytu (červené obdelníky). Oči vyhledáváme pomocí metody srovnávání se vzorem. Oko se nachází v místě největší shody vzoru a obrazu.
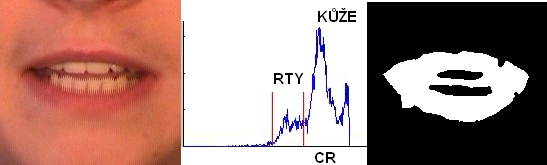
Obrázek: Jestliže známe přibližný tvar hlavy provedeme nalezení významných bodů. Jako první nalezneme oči. Pro každého řečníka vytvoříme vzor pro levé a pravé oko. Protože známe umístění očí na obličeji a nalezený tvar obličeje, můžeme určit přibližné místo výskytu (červené obdelníky). Oči vyhledáváme pomocí metody srovnávání se vzorem. Oko se nachází v místě největší shody vzoru a obrazu.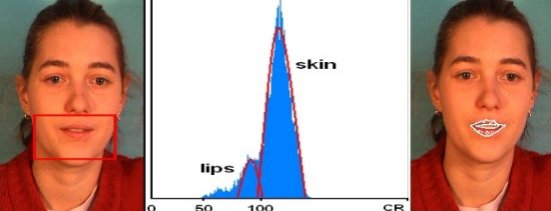 Obrázek: Další významný bod představují ústa řečníka. Zde využijeme toho že ústa by měli být vždy červenější než okolní kůže. Můžeme přibližně určit pozici úst protože známe pozice očí. Z této oblasti spočítáme histogram pro barevnou složku CR z reprezentace barev YCBCR. Víme že v této oblasti se nacházejí dva dominantní objekty: kůže a ústa. Těmto objektům odpovídají i objekty v histogramu. Můžeme tedy automaticky nalézt práh, oddělující oba objekty od sebe. Pomocí metody prahování získáme binární objekt rtů řečníka.
Obrázek: Další významný bod představují ústa řečníka. Zde využijeme toho že ústa by měli být vždy červenější než okolní kůže. Můžeme přibližně určit pozici úst protože známe pozice očí. Z této oblasti spočítáme histogram pro barevnou složku CR z reprezentace barev YCBCR. Víme že v této oblasti se nacházejí dva dominantní objekty: kůže a ústa. Těmto objektům odpovídají i objekty v histogramu. Můžeme tedy automaticky nalézt práh, oddělující oba objekty od sebe. Pomocí metody prahování získáme binární objekt rtů řečníka.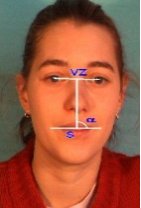 Obrázek: Posledním krokem je určení oblasti zájmu. Oblast zájmu představují rty a nejbližší okolí. Musíme určit střed oblasti S, natočení hlavy a velikost ROI VZ.
Obrázek: Posledním krokem je určení oblasti zájmu. Oblast zájmu představují rty a nejbližší okolí. Musíme určit střed oblasti S, natočení hlavy a velikost ROI VZ.Dosažené výsledky
2004
- nahrána audiovizuální databáze HSCAVC pro 100 řečníků
- databáze slouží k ověřování metod audiovizuálního rozpoznávání
- složení řečníků: 39 mužů 61 žen
- databáze obsahuje 200 foneticky vyvážených vět
2005
- proveden přepis promluv v audiovizuální databázi HSCAVC
- vytvořen algoritmus pro nalezení hlavy, očí a trů řečníka běhen promluvy
- algoritmus je založen na metodě headtrackingu a liptrackingu prezentované na konferenci SPECOM2004 a ICLSP2004
- provedeno první předzpracování korpusu HSCAVC
- pro každou nahrávku byla určena pozice středu rtů a veliskost oblasti zájmu
- výsledky plus popis nahrávání korpusu byly prezentovány na konferenci AVSP2005
- vylepšen algoritmus nalezení rtů o přesné nalezení vnitřní a vnější kontury rtů
- byla využita metoda ACM (active contour model)
- vylepšení algoritmu nalezení rtů o zpracování vnitřku úst
- dodány algortimy pro detekci zubů a jazyka uvnitř úst
- vytvořena první parametrizace vizuálních promluv založená na metodě DCT
- DCT koeficienty jsou používány jako standardní parametrizace vizuálních složky řeči
- vyzkoušení DCT parametrizace na anglickém audio vizuální korpusu XM2VTSDB
- bylo provedeno rozpoznávání číslic v souvyslích větách s úspěšností 55%
- DCT paramtrizace bude použita k porovnání úspěšnosti námi navržené parametrizace
- provedena analýza českých fonémů z hlediska vizuální informace
- analýza byla provedena pro 3 řečníky
- bylo nalezeno 13 vizémových skupin podobně jako to uvádí literatura pro výuku odezírání řeči
- výsedky byly prezentovány na konferenci SPECOM2005
- návrh vlastní parametrizace vizuální složky řeči
- parametrizace je založena na geometrickém popisu rtů a jejich okolí tak aby bylo možné využít poznatky expertů na odezírání řeči
- parametrizace je navržena s ohledem na nezávislost na řečníkovi