



Information retrieval
Content
The task of information retrieval (IR) system is to present a user with a list of documents (sorted according to decreasing relevance) which would best satisfy the user’s information need expressed by the query entered in natural language. Thus, ideally, the IR algorithms are able to perform correct semantic analysis of both the documents in the collection and the entered query. This goal was still not reached in practice, but even partial success in the development of IR methods substantially helps the users to find the information they need. The techniques that are currently being used at our lab as well as by the international leaders of the field approximate the semantic content of both the document and the query by statistical analysis of word n-grams occurring in the given document and/or query. That way we can assess a degree of similarity between the document and the query and consequently use this similarity as the measure of relevance. Similar methods are also used for document categorization and clustering, and segmentation of uninterrupted text streams. The reader should bear in mind that the definition of the term “document” differs for different tasks – it could refer to anything from entire works of literature, web pages, and newspaper articles to the smallest units like a paragraph or even a single sentence.
Our lab focuses mostly on information retrieval from speech data (often called "spoken document retrieval" or "speech retrieval") where the task is further complicated by the presence of speech recognition errors. When developing our methods, we try to make the best use of the fact that our speech recognition engine produces not only the best (most probable) transcription of the given audio track but also the whole network (so-called lattice) of the most probable hypotheses together with a confidence measure determining their reliability.
The special subtask of the speech retrieval is a so-called spoken term detection where the system looks for individual words and/or short phrases in the stream of audio data. We have developed a system performing this task that allows users to search for key-phrases and replay passages containing them in the Czech part of the large audiovisual archive containing the testimonies of the Holocaust survivors (approx. 1,000 hours of video – for more details about the archive see http://dornsife.usc.edu/vhi). Since this application can search both the word and the phoneme representation of the individual recordings, it enables to find even the words that are not present in the lexicon of the speech recognition system. The software is currently being prepared for installation in the MALACH Center of Visual History (http://ufal.mff.cuni.cz/cvhm/)
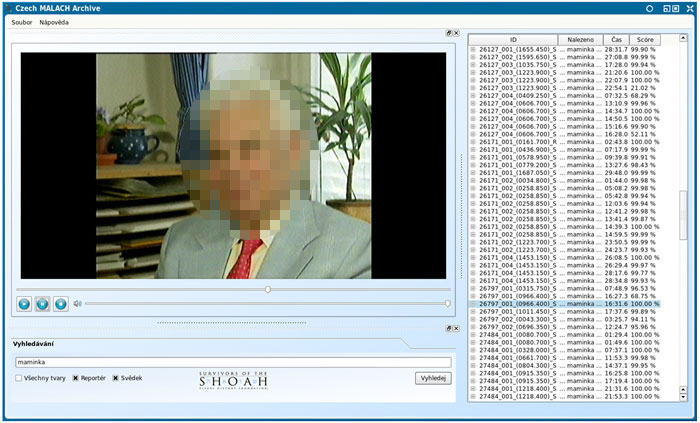
However, many research outcomes in the IR field suggest that by far the best retrieval performance can be achieved when the data in a given archive are tagged beforehand using keywords from a well-defined controlled vocabulary (thesaurus), often hierarchically structured.
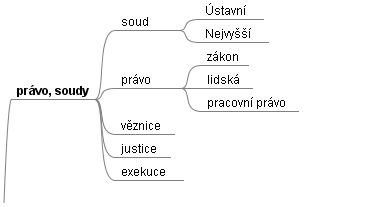
The preparation and/or selection of the appropriate thesaurus together with the design of the methods for assisted cataloguing (keyword assignment) is currently one of the research focuses of the joint project with the Czech Television.
State-of-the-art techniques for speech recognition and text-to-speech synthesis from our lab were integrated with the advanced natural language processing algorithms developed at Institute of Formal and Applied Linguistics within the EC project COMPANIONS to develop a dialogue system which is (to a limited degree) able to engage in a conversation about a user’s family photographs.