



Audiovizuální korpus UWB-05-HSCAVC
Obsah stránky
Jedním z problémů audiovizuálního rozpoznávání řeči je neexistence nebo nedostupnost kvalitních audio vizuálních databází. Je to způsobeno obtížností nahrání takové databáze, kterou představuje především uchování a předzpracování velkého množství obrazových dat. Většina databází je pořízena pro anglický jazyk. Pro český jazyk existuje pouze jedna audiovizuální databáze vytvořená na pracovišti kybernetiky v Liberci odkaz, která ovšem obsahuje pouze izolovaná slova pro X řečníků. Protože naším cílem bylo ověření metod audiovizuálního rozpoznávání na spojité řeči bylo nutné vytvoři vlastní databázi UWB-05-HSCAVC (University of West Bohemia - 2005 - hunderd speakers Czech audiovizual corpus). Cílem při tvorbě databáze bylo vytvořit rozsáhlou audiovizuání databází pro spojitou češtinu, kde bude možné zkoumat vizuální řeč, jednoduše a s dostatečnou přesností získat vizuální popis řeči a otestovat metody pro audiovizuální rozpoznávání řeči. Databáze byla pořízena v rámci projektu Musslap, který se zabývá zpracováním audiovizuální řečové informace a znakové řeči.
Ukázky video záznamů pro různé řečníky:
(AVI (Xvid) ke stažení: Ukázka 1, Ukázka 2, Ukázka 3)Flash Player
Základní parametry korpusu
- Počet řečníků: 100, 39 mužů, 61 žen
- Jazyk: čestina
- Počet promluv: 200 spojitých vět pro každého řečníka, prvních 50 vět společných pro všechny řečníky.
- Typ promluv: spojitá řeč, foneticky vyvážené promluvy pro každěho řečníka
- Video záznam: čelní pohled, rozlišení - 720*576*25fps, komprese - DV codec
- Akustický záznam: 2 mikrofony, 44kHz, 16 bit, PCM
Nahrávací podmínky
Pro nahrávání korpusu byly zvoleny laboratorní podmínky, které umožňují využití jednoduchých metod pro detekci obličeje řečníka a následného získání vizuálních parametrů. Schéma nahrávání promluv je zobrazeno na obrázku 1. Snímána byla celá hlava řečníka z čelního pohledu. V průběhu promluvy je hlava řečníka statická. Při snímání bylo použito jednotné pozadí a nasvícení pomocí dvou světelných zdrojů, čímž bylo v průběhu nahrávání docíleno malích změn v osvětlení. Pro záznam zvuku byly použity dva mikrofony. Jeden stolní mikrofon umístěný před řečníkem a druhý klopový mikrofon umístěný na hrudníku řečníka.
 Obrázek: Nahrávání korpusu.
Obrázek: Nahrávání korpusu.
Řečník byl snímán jendou kamerou digitální kamerou SONY DCR-TRV 740E. Kamera byla umístěna naležato, aby hlava řečníka zabírala co největší čast obrazu. Rozlišení video záznamu je 720*576 pixelů se snímkovací frekvencí 25 fps. Vizuální data byla kompromována pomocí DV kodeku. Díky prokládanému snímacímu režimu kamery je možné zvýšit snímkovací frekvenci z 25 na 50 fps při snížení vertikálního rozlišení z 576 na 288 pixelů. Snížení vertikálního rozlišení je akceptovatelné, neboť hlava řečníka zabírá (díky snímání kamerou naležato) velkou část snímací oblasti a proto je rozlišení připadající na hlavu a rty řečníka dostačující. Akustický záznam byl uložen ve formátu PCM s vzorkovací frekvencí 44kHz, a rozlišením 16bitů. Bližší informace o databázi je možné nalézt v článku
Promluvy
Každý řečník promlouval 200 spojitých vět, což představuje 23 minut záznamu. Věty byly náhodně vybrány z novinových textů, tak aby slňovali základní požadavky z hlediska fonetického vyvážení textu. Prvních 50 vět je totožných pro všechny řečníky. Jedná o delší věty obsahující průměrně 15 slov. Tyto věty byly vybrány tak, aby obsahovaly co největší množství všech fonémů. Ostatních 150 vět je odlišných pro každého řečníka. Tyto věty slouží k vyvážení promluv řečníka tak, aby v nich byl výskyt fonémů podobný jako v běžně používaném jazyce. Počet slov ve větach byl limitovám schopností řečníků číst a reprodukovat text jako spojité promluvy.
Popis zpracování databáze
Po záznamu dat bylo provedeno předzpracování databáze. Akutický a vizuální záznam byly nahrány odděleně a pro jejich synchronizaci byla použita klapka. Všechny promluvy byly ručně anotovány pomocí programu Transcriber a záznamy byly rozsekány na jednotlivé věty, které byly uloženy. Bylo provedeno nalezení hlavy řečníka pomocí (metody odstranění pozadí a nalezení vnitřní a vnější kontury rtů).
Ukázky nalezení hlavy a nalezení rtů:
(AVI (Xvid) ke stažení: Nalezení kontury rtů 1, Nalezení kontury rtů 2, Liptracking)Flash Player
Popis uložení
Po předzpracování vizuálních a akustických záznamů byla všechna data uložena na DVD nosiče. Data pro každého řečníka byla uložena na samostatné DVD s následující strukturou:
avi
video soubory 001..200.avi ukázka - 28.avi
description
soubory 001-1..200-1.jpg obsahují první frame video záznamu pro danou větu s označením nalezených očí a středu úst ukázka - 001-1.jpg
{kind=link}
soubory 001-2..200-2.jpg obsahují poslední frame video záznamu pro danou větu s označením nalezených očí a středu úst ukázka - 001-2.jpg
{kind=link}
soubory 001..200.txt obsahují popis pozice ust, natočení hlavy a vzdálenost očí pro všchny framy ukázka - 001.txt
template
kuze.bmp – soubor obsahující pouze kůži pro náhodný frame odkaz na soubor ukázka - kuze.jpg
{kind=link}
nos.bmp – výřez oblasti nosu odkaz na soubor ukázka - nos.jpg
{kind=link}
okod.bmp – výřez oblasti levého oka odkaz na soubor ukázka - okod.jpg
{kind=link}
okoh.bmp – výřez oblasti pravého oka odkaz na soubor ukázka - okoh.jpg
{kind=link}
trs
soubory 001..200.trs obsahují anotaci odkaz na soubor ukázka - 001.trs
wav
soubory 001..200.wav obsahují akustický záznam promluvy odkaz na soubor ukázka - 001.mp3
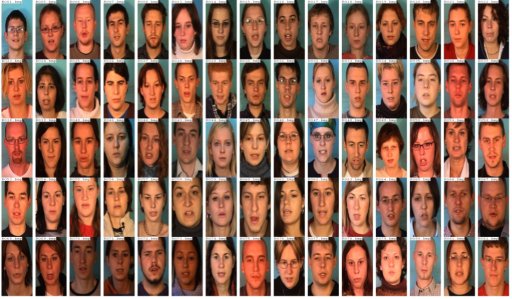 Obrázek: Řečníci.
Obrázek: Řečníci.