



Acoustic speech synthesis
Content
Acoustic speech synthesis is a process (or a method, respectively) of speech signal production. The aim of speech synthesis is to generate speech, in such form and quality that synthetic speech follows as closely as possible the characteristics of human speech (often even the voice of a concrete person); not just the voice itself and its quality, but also the style of speaking, etc. To produce speech automatically by a machine, text-to-speech (TTS) technology is used. Its task is to convert any text to the corresponding speech. Thus, TTS can be viewed as a set of special modules and algorithms that provide automatic conversion of written text to speech. The modules include word processing (e.g. analysis and normalization), conversion of text to its pronunciation form (i.e. phonetic transcription and prosody generation), and speech production itself. For the speech production, two approaches are currently dominant:
- signal-based approach, in which the resulting speech is produced by a concatenation of properly selected speech segments (speech units) like context-dependent phones, diphones, or halfphones (with unit selection being a well-known representative of this approach);
- model-based approach, in which the resulting speech is produced from (speech production) models (statistical parametric synthesis, or hidden Markov model based synthesis, in which speech is produced from statistical models, is the most popular representative of this approach).
Application of speech synthesis
Speech synthesis systems can be applied widely—in areas where other means of communication than human voice are out of question, in areas where the possibility of voice communication significantly enhance the quality of human activity, or simply in areas where synthesized voice can make human life easier. Synthesized speech can replace a real human speaker on a wide range of different positions—from the routine reporting of repetitive information (bus stops, railway stations, etc.), voice monitoring (control centres), information and dialogue systems (automatic switchboard, call centres), to highly sophisticated and natural reading of any text (emails, text messages, books). At present, speech-synthesis technology begins to find application also in the entertainment industry.
Nevertheless, the most useful applications of speech-synthesis technology are undoubtedly those for people with various impairments. They can be used by people with different visual, hearing or voice impairments. Visually impaired can use a text-to-speech system that reads any text for them (for instance, this is what a screen reader does). Voice impaired can use a text-to-speech system to speak for them (in their own voice, preferably) or to learn them speak again. Hearing impaired can prefer listening to neutral, well-coarticulated, and noise-free synthetic speech instead of listening to natural, noisy, and dynamic speech. People with minor hearing impairment can also use a talking head in which synthetic speech is supplemented with visual information (lip reading, etc.). Speech synthesis can also help in teaching and learning sign language for hearing unimpaired.
Czech speech synthesis
For the purposes of Czech speech synthesis, a modern high-quality concatenation-based speech-synthesis method is developed at our workplace. In short, the basic principle of this method is the representation of important acoustic events of human speech using appropriate speech units. The resulting speech is then made up by a concatenation of the properly selected units (unit selection). Each unit is selected according to a number of phonetic, prosodic, and linguistic criteria.
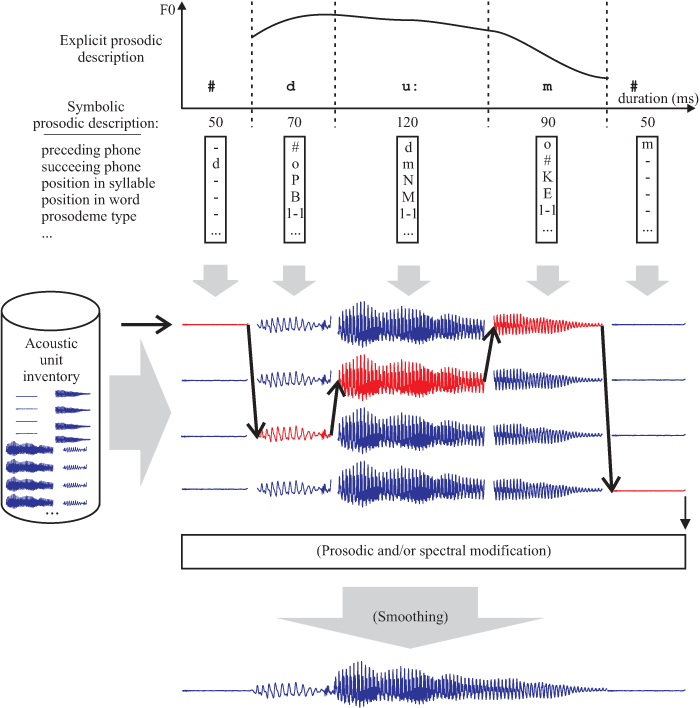
The key to successful unit-selection speech synthesis is the careful preparation of an inventory of speech units. Since the quality of the resulting synthetic speech to a large extent depends on the richness of speech segments contained in the inventory and the accuracy with which these segments are extracted from reference utterances, an automatic inventory construction method based on a large number of real speech utterances is employed at our workplace. Automation is an important aspect of our system because it allows to create very precise, acoustically and linguistically “rich” (it is possible to use large speech corpora—dozens of hours of speech, i.e., thousands of sentences) inventory of acoustic units very quickly. Such approach is also known as corpus-based because the speech corpus (i.e. a set of real speech utterances spoken by a single voice talent, whose voice then speech synthesizer “speaks”, and their representation in orthographic, phonetic, prosodic or spectral domains) is the basic material for creating the speech unit inventory.
Experiments with the model-based approach, namely hidden Markov model (HMM) based speech synthesis, have also been carried out at our workplace. In short, the principle of this approach is to model speech units using statistical methods, and the resulting speech is then generated from a composite model composed of models of each unit. Although large speech corpora should also be used to train the models (thus, this approach is also called corpus-based), the trained models can be then adapted to match characteristics of some other voice. In this way, new synthetic voices can be built very quickly without the need to collect thousands of recordings of a new voice.
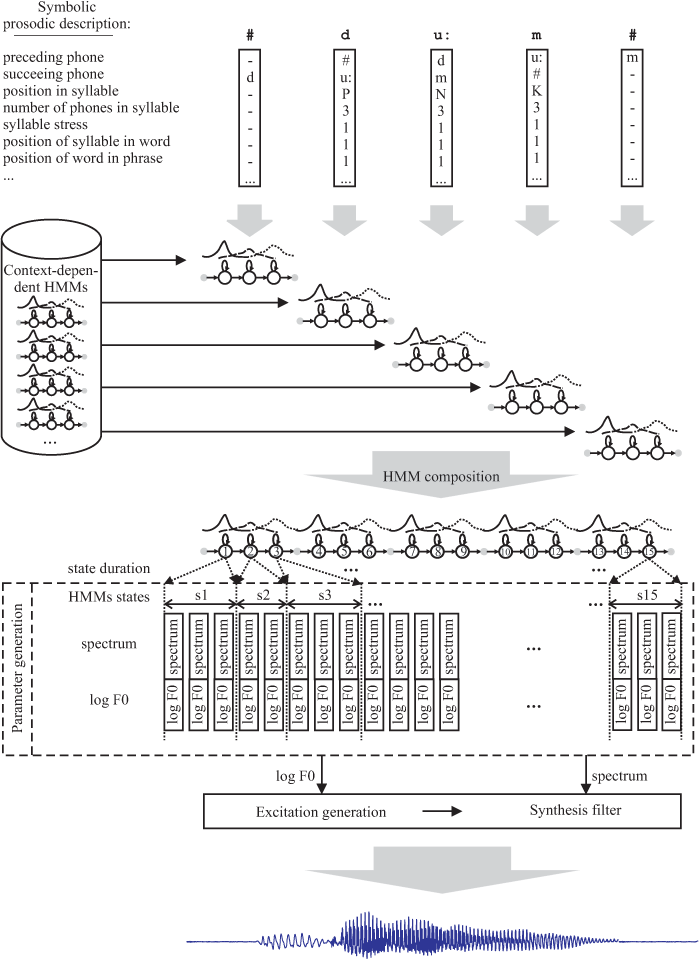
An important quality criterion is the naturalness of resulting synthetic speech. The naturalness of speech to a large extent depends on the quality of modelling the prosodic features of speech (simply spoken, such features describe utterance melody waveform and volume and duration of individual segments of speech). For our system, a unique method for modelling and selection of natural prosodic feature waveforms extracted from real speech utterances was proposed.
Samples
-
Sample - Czech, unit selection method, woman, Petra (MP3 to download)
Flash Player
-
Sample - Czech, unit selection method, man, Jan (MP3 to download)
Flash Player
-
Sample - Czech, unit selection method, woman, Radka (MP3 to download)
Flash Player
-
Sample - Czech, unit selection method, woman, Iva (MP3 to download)
Flash Player
-
Sample - Czech, unit selection method, man, Standa (MP3 to download)
Flash Player
-
Sample - Slovak, unit selection method, woman, Melánie (MP3 to download)
Flash Player
-
Sample - Czech, HMM (Hidden Markov Model) method, speaker Václav Havel (MP3 to download)
Flash Player
-
Sample - TTS usage for automatic dubbing (AVI to download)
Flash Player